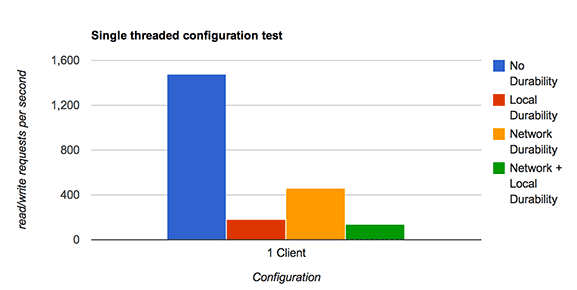
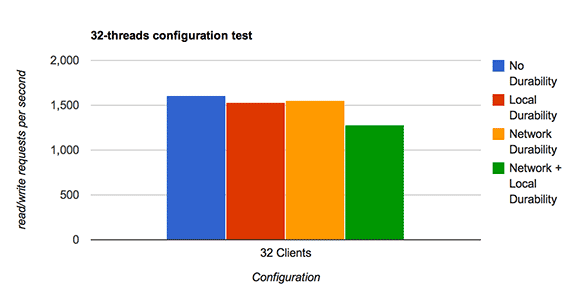
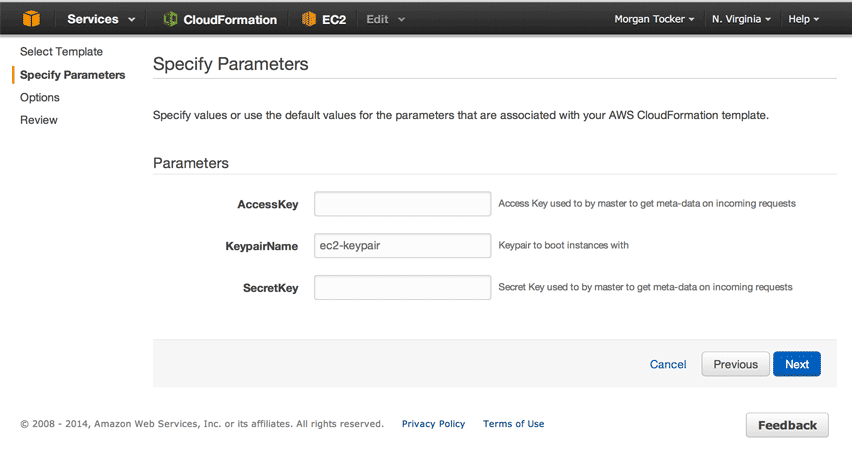
Thank you to the MySQL Community, on behalf of the MySQL team @ Oracle. Your bug reports, testcases and patches have helped create a better MySQL 5.6.19.
In particular:
- Thank you to Daniël van Eeden for reporting that the utility charset2html was unmaintained and obsolete. We followed Daniël’s suggestion and removed it from MySQL distributions. Bug #71897.
- Thank you to Dario Kampkaspar for reporting that upgrading from 5.6.10 to a more recent 5.6 release would fail. Bug #72079.
- Thank you to Fangxin Flou for reporting that InnoDB would call memset too often. Fangxin also provided a suggested patch to fix the issue. Bug #71014.
- Thank you to Daniël van Eeden for reporting an assertion when enabling the innodb_table_monitor. Bug #69641.
- Thank you to Domas Mituzas for reporting an off by one error in the handling of innodb_max_dirty_pages_pct. Thanks also to Valeriy Kravchuk for suggesting that the value be a float, and Mark Callaghan for providing a sample patch. Bug #62534.
- Thank you to Guangpu Feng for reporting an issue where an aborted TRUNCATE TABLE command could still be written to the binary log. Guangpu also provided detailed code-analysis, which helped with our investigation. Bug #71070.
- Thank you to Justin Swanhart for reporting an issue where the server did not always correctly handle file permissions on the auto.cnf file. Bug #70891.
- Thank you to Frédéric Condette for reporting an issue when using replication with GTIDs and replicate-ignore-db. Bug #71376.
- Thank you to Michael Gmelin for reporting compilation errors when building in C++11 mode. Michael also provided a patch with a suggested fix. Bug #66803.
- Thank you to Hartmut Holzgraefe for reporting that CMake produced not-useful warnings. Bug #71089.
- Thank you to John Curtusan for reporting that on Windows REPAIR TABLE and OPTIMIZE TABLE failed on MyISAM tables with .MYD files larger than 4GB. Bug #69683.
- Thank you to Elena Stepanova for reporting an issue that could break row-based replication. Elena also managed to reduce the issue down to a simple test case. Bug #71179.
- Thank you to Yu Hongyu for reporting that an UPDATE statement could fail to update all applicable rows. Bug #69684.
- Thank you to Tom Lane for his comments on why the test “outfile_loaddata” could be failing. His suggestion proved to be correct, and helped tremendously in tracking down the root cause. Bug #46895.
In Addition:
- We thank the MySQL Community for their feedback on our proposal to deprecate unused command line programs. The mysqlbug, mysql_waitpid, and mysql_zap utilities are now deprecated in 5.6.19, and will be removed in 5.7.
Thank you again to all the community contributors listed above. If I missed a name here, please let me know!
Please also note:
There was no MySQL Community Server 5.6.18. That version number was used for an out-of-schedule release of the Enterprise Edition to address the OpenSSL “Heartbleed” issue. This issue did not affect the Community Edition because it uses yaSSL, not OpenSSL, so a new release of the Community Server was not needed, and 5.6.17 is followed by 5.6.19.
– Morgan