If you read Yoshinori’s post about Semi-sync at Facebook, he lists the objective of using semi-sync as an alternative to running full durability on a master. That is to say that once you can guarantee writes have safely been shipped across the network, you may not strictly need to guarantee that they are safe locally.
This is something that I have been wanting to benchmark for a long time, and reading Jay’s post about Semi-sync replication performance in MySQL 5.7 DMR4 and a conversation in last week’s #dbhangops inspired me to explore this in more detail. For my tests, I will be using Master-Slave replication and three alternative definitions of durability:
- Local Durability. By ensuring that sync_binlog=1 and innodb_flush_log_at_trx_commit=1 any changes that are committed locally will be crash-safe (provided that underlying hardware does not lie). A slave will be connected, but using asynchronous replication.
- Network Durability. By enabling semi-sync replication, each change will be guaranteed on more than one machine. However, each machine will take a relaxed view to how safe the changes are locally (sync_binlog=0, innodb_flush_log_at_trx_commit=0). This is the MySQL Cluster definition of durability, and also some NoSQL systems. It requires that each replica has physical isolation (in the case of AWS: an availability zone).
- Local + Network Durability. This is a strict definition where both semi-sync and network durability is employed. While it might seem excessively strict, what I like about this option, is that it has the potential to reduce administrative costs during failure events.
Testing
Basic setup details:
- AWS EC2 m3.medium instances
- Master in us-east-1b, slave in us-east-1d
- Latest Amazon Linux AMI
- MySQL 5.7 DMR4
- Datadir stored on 40GB Provisioned IOPS EBS volume (900 IOPS)
- sysbench 0.5 update_index.lua test
I measured both the network latency (ping) and disk latency (dd bs=512 count=1000 if=/dev/zero of=testfile oflag=dsync) prior to starting the test. Interestingly, both were the same at about 2ms.
My first test was to compare single threaded performance:
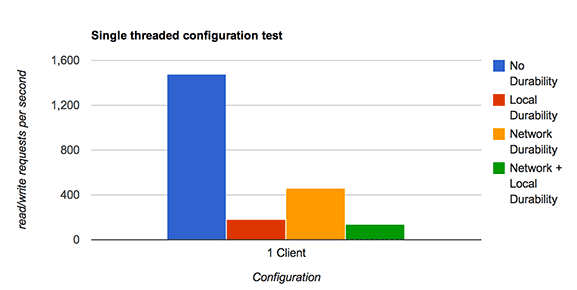
I would say that the results are somewhat as expected:
- Performance when not durable is awesome! (but probably not useful)
- Local durability is quite expensive in single-threaded workloads. There is not much opportunity for group-commit, and the 2ms latency I have for an fsync hurts to be able to safely write the InnoDB redo logs + the binary logs.
- Network durability actually performs better than local durability.
- The combination of Local+Network durability is worse than network only or local only.
Now to repeat the same test, but in 32-threads:
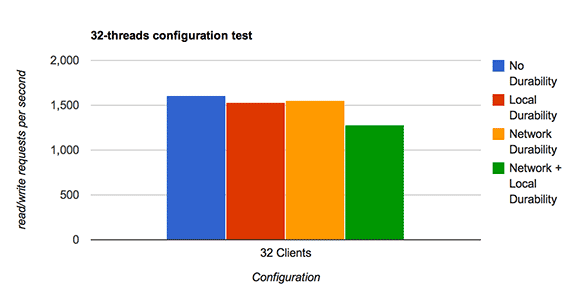
What is interesting to note is that:
- No durability still performs the best, but by a much smaller margin.
- The improved group-commit in MySQL 5.6+ is really helping the local durability throughput increase.
- Network durability is marginally ahead of local durability.
- Network+Local is about 15% worse than just local durability.
Comparing Local versus Network Durability
So network durability scored better than local in both tests!?
I think at this point it’s important to explain the difference between local and network durability in the event of a crash, using our current set of tools that are available. If we are using asynchronous replication with a durable local master, and crash safe slaves, then resuming replication is actually possible in the event of a crash. This is not true in the case of network durability, as writes could be lost on the failing machine. This is an important loss of functionality that is difficult to justify.
I would also point out that I think it is easier to hardware-accelerate local durability than it is network durability. The local fsync speed can be improved with an SSD or a RAID Controller with a battery-backed write cache. Network latency can be lowered too, but it might be harder to do so while keeping physical isolation.
Conclusion
For the reasons I listed, I still think local durability is still more useful when choosing just one option for durability. But at the same time, semi-sync is no slouch and it’s great to see new developments in this area in MySQL 5.7.
What I did not test, is configuring MySQL to be mostly-durable locally, and fully network durable. There is a lot of potential to meet somewhere in the middle and very selectively disable features such as the InnoDB doublewrite buffer.
I do not think it is fair to label semi-sync as “slow”, and I am hoping to convince more users that they should take a look 🙂
